Claude Fable 5 ist das erste LLM aus einer neuen Modellfamilie "Fable" von Anthropic. Fable basiert auf dem bereits zuvor vorgestellten Modell Claude Mythos und wurde am 9. Juni 2026 veröffentlicht. Das Modell lässt sich über die API oder die Claude AI App nutzen, unterliegt aber strengen Sicherheitsrichtlinien und blockt alle Anfragen in Richtung Cybersecurity automatisch ab.
Fable stellt eine neue Modellfamilie, noch über der bislang stärksten "Opus"-Reihe von Claude Modellen dar. Fable 5 erreicht einen großen Sprung gegenüber Opus 4.8 in so gut wie allen Benchmarks. Es bietet ein 1-Mio.-Token-Kontextfenster, adaptives Reasoning und kann über Claude Code auch auf neue Features des Harnesses, wie z.B. den "Ultracode" Modus zugreifen.
Websuche, Bildgenerierung, Computer Use und MCP-Server.
Multimodalität
Das Modell kann Text, Bilder, Audio und PDFs als Input verarbeiten.
Finetuning
Finetuning des Modells ist aktuell nicht möglich.
Details zum Modell
Max. Input
1 Mio. Token
Max. Output
128k Token
Trainingsdaten
Unbekannt
Parameter
Unbekannt
Input Preis
10,00 $
Output Preis
50,00 $
Vokabular
Unbekannt
Dateigröße
Unbekannt
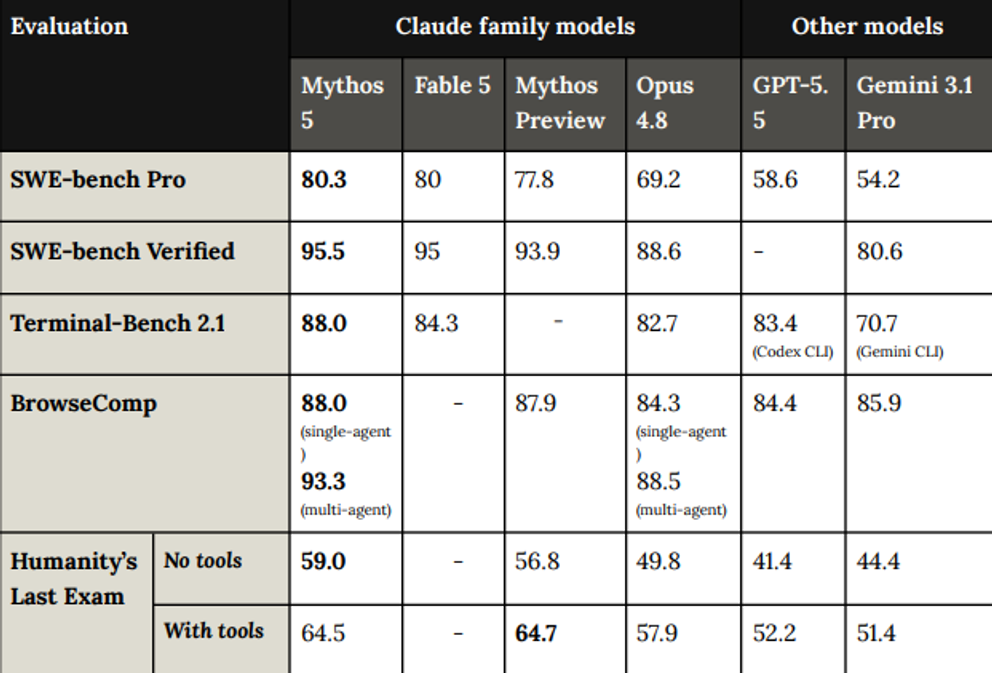
Claude Fable 5 Benchmark Scores
Im KI-Kontext bezeichnet Performance die Leistungsfähigkeit eines Modells in Bereichen wie Sprachverständnis, Logik oder Programmierung – gemessen anhand standardisierter Benchmarks zur objektiven Vergleichbarkeit.
Technologie & Daten
Technische Spezifikationen
Architektur
Proprietärer Transformer
Input Kontextlänge
1 Mio.
Output Kontextlänge
128k
Tokenizer
Proprietärer Tokenizer
Besonderheiten
Sicherheits-Fallback auf Opus 4.8
Bei Hochrisiko-Anfragen (Cybersecurity, Biotech etc.) wird automatisch auf Opus 4.8 gerouted.
Vorteile & Nachteile
Vorteile
Leistungsstärkstes Modell von Anthropic
Die Mythos-, bzw. Fable-Modellfamilie reiht sich oberhalb der Opus-Reihe ein. Fable 5 erreicht State-of-the-Art Ergebnisse bei agentic Coding, Wissensarbeit, Vision und Computer Use.
Führendes Coding-Modell
Fable 5 erreicht überragende 95,0% im SWE-bench Verified Benchmark und 80,3% in SWE-bench Pro. Damit liegt es deutlich vor GPT-5.5 und Gemini 3.1 Pro.
Starke Ergebnisse in Vision und Computer Use
In OSWorld-Verified erreicht Fable 5 85,0%, eine neue Bestmarke unter den Claude-Modellen.
1-Mio. Token-Kontextfenster
Fable 5 kann auf ein großes 1 Mio. Token-Kontextfenster zugreifen. Dabei arbeitet es länger autonom und – laut Anthropic – bei höherer Token-Effizienz als frühere Claude-Modelle.
Nachteile
Sehr hoher Preis
$10 / 1 Mio. Input- und $50 / 1 Mio. Output-Tokens machen Fable 5 genau doppelt so teuer wie Claude Opus 4.8 ($5/$25).
Eingeschränkte Verfügbarkeit
In Pro-, Max-, Team- und Enterprise-Abos von Claude AI ist Fable 5 nur bis zum 22.06.2026 ohne Aufpreis enthalten. Anschließende Nutzung läuft voraussichtlich zunächst nur über die API (Credit-System).
Guardrails schränken Fähigkeiten ein
In Cybersecurity, Biologie/Chemie und Distillation wird automatisch auf Opus 4.8 gerouted, mit entsprechend "schlechterer" Leistung in diesen Bereichen.
Vergleiche Claude Fable 5 mit anderen LLMs
Vergleiche Claude Fable 5 mit anderen Sprachmodellen anhand wichtiger Metriken wie Kontextgröße, Parameteranzahl, Preisen und Benchmark-Leistung.
Das Modell ist derzeit bei keinen Anbietern verfügbar.
Mit Claude Fable 5 macht Anthropic erstmals ein Modell auf Basis von Claude Mythos öffentlich zugänglich. Zwar eingeschränkt, dafür aber mit Benchmark-Ergebnissen auf einem vollständig neuem Niveau.
1. Was ist Claude Fable 5?
Claude Fable 5 ist das neue Frontier-Modell von Anthropic und wurde am 9. Juni 2026 veröffentlicht. Fable gründet damit eine neue Modellfamilie, die noch über der Opus-Reihe steht. Fable 5 basiert auf dem Claude Mythos Modell, das Anthropic bislang ausschließlich ausgewählten Cyber-Defense-Partnern im Rahmen von Project Glasswing zur Verfügung gestellt hat.
Fable 5 ist entsprechend das erste Mythos-Modell, das du regulär über die Claude App und die API nutzen kannst. Technisch basiert es auf exakt denselben Modellgewichten wie Claude Mythos 5. Der Haupt-Unterschied liegt tatsächlich in den Safeguards: Fable 5 wird mit zusätzlichen Sicherheits-Klassifizierern ausgeliefert, die Anfragen in Hochrisiko-Bereichen wie Cybersecurity und Biologie abfangen (mehr dazu in Abschnitt 2).
Zahlenden Claude AI Nutzer steht Claude Fable 5 in der Modellauswahl zur Verfügung.
Einordnung in die Anthropic-Modellfamilie
Anthropic fährt damit ab sofort eine vierstufige Modell-Hierarchie: Haiku (schnell und günstig), Sonnet (ausgewogene Preis-Leistung), Opus (bisheriges Flaggschiff) und neuerdings Fable bzw. Mythos an der Spitze.
Bei Byte haben wir Fable 5 seit dem Launch im Einsatz und in unsere Claude-Code-Workflows integriert. Unsere ersten Eindrücke fließen in diesen Artikel ein. Unserer Findings und die Benchmark-Ergebnisse aus der offiziellen System Card haben wir auf dieser Seite für dich aufbereitet.
2. Die wichtigsten Neuerungen von Claude Fable im Überblick
Der Fable Safety-Classifier mit Fallback auf Opus
Die größte Auffälligkeit bei der Nutzung von Fable 5 ist das Klassifizierer-System. Im Hintergrund pürfen separate KI-Systeme jeden Prompt auf drei Themenfelder: Cybersecurity, Biologie/Chemie und Distillationsversuche. Schlägt ein Classifier an, beantwortet nicht Fable 5 deine Anfrage, sondern automatisch Claude Opus 4.8. In der Claude App erhältst du dann einen entsprechenden Hinweis.
Laut Anthropics eigenen Angaben greift dieser Mechanismus in weniger als 5 % aller Sessions. In der Praxis bedeutet das demnach, dass 95 % der Nutzung Fable 5 dem unbeschränkten Mythos 5 entspricht. Zum Launch sind die Filter noch sehr streng eingestellt, es lässt sich davon ausgehen, dass diese mit der Zeit etwas gelockert werden.
In der Messages API gibt es keinen automatischen Fallback. Geblockte Anfragen liefern
stop_reason: "refusal"
als strukturierten Output zurück. Den Opus-Fallback kannst du serverseitig optional aktivieren. Wichtig, wenn du Fable 5 in eigene Apps integrieren solltest.
Claude Fable 5 kann bis zu 12 Stunden autonom am Stück arbeiten
Fable 5 kann deutlich länger selbstständig an Aufgaben arbeiten als alle bisherigen Claude-Modelle.
Early-Access-Nutzer berichten von Sessions, in denen das Modell neun bis zwölf Stunden am Stück an mehrseitigen Spezifikationen arbeitet, dabei eigene Sub-Agenten startet, Rechercheergebnisse gegeneinander testet und Notizen über den eigenen Fortschritt führt.
Je länger und komplexer die Aufgabe, desto größer fällt laut Anthropic der Vorsprung gegenüber Opus aus.
Verbesserte Vision- und Memory-Fähigkeiten
Auch bei der Bildverarbeitung scheint Fable 5 einen deutlichen Sprung gegenüber vorigen Modellen gemacht zu haben. Fable liest präzise Werte aus wissenschaftlichen Diagrammen aus und rekonstruiert Web-Apps allein anhand von Screenshots.
Anthropic selbst hat Fable 5 die Pokémon FireRed Edition anhand von reinen ingame-Screenshots durchspielen lassen. Frühere Modelle benötigten dafür einen Hilfs-Harness.
3. Benchmarks: Wie gut ist Claude Fable 5 wirklich?
Eine genau Aufschlüsselung der Benchmark Ergebnisse von Fable 5 kannst du oben auf dieser Seite einsehen.
Zusammengefasst erreicht das neue Modell auf nahezu allen von Anthropic getesteten Benchmarks State-of-the-Art-Werte, häufig mit deutlichem Abstand. Wir konzentrieren uns hier auf die Coding-Kategorie, da diese aktuell im professionellen Einsatz am relevantesten ist.
Alle Scores stammen aus dem offiziellen System Card und den Launch-Materialien.
Auch in bereits gesättigten Benchmarks kann das neue Modell überzeugen. In SWE-bench Verified werden 95% erreicht, in Terminal-Bench 2.1 ganze 84,3%.
Noch interessanter ist FrontierCode von Cognition: Der Benchmark testet, ob Modelle schwierige Coding-Aufgaben lösen und dabei die Qualitätsstandards produktionsreifer Codebases einhalten. Fable 5 führt hier selbst auf mittlerer Effort-Stufe vor allen anderen Modellen auf maximaler Stufe. Mit steigendem Reasoning-Budget steigert sich der Score von rund 11,5 % (low) auf 30,9 % (max).
4. Claude Fable 5 in der Praxis: Erste Erfahrungen
Wir haben erste Stimmen von Usern gesammelt, die Early-Access zu Claude Fable 5 hatten.
AI-Researcher Andrej Karpathy ordnet dem Fable 5 Release qualitativ als echten Generationssprung ein, vergleichbar mit dem Schritt zu Claude 4.5 im Winter 2025. Sein Rat deckt sich mit unserer Erfahrung: Man kann Fable 5 deutlich ambitioniertere Aufgaben geben, als man es von bisherigen Modellen gewohnt ist. Das Modell versteht die Intention, interpretiert viele Unbekannten richtig und zieht sie durch.
Wharton-Professor Ethan Mollick, der das Modell auch als Externer vorab testen konnte, beschreibt für sich einen Wandel in seinen Arbeits-Workflows: In seinen Experimenten arbeitete Fable 5 bis zu 9,5 Stunden autonom an einzelnen Tools, orchestrierte dabei eigene Recherche-Agenten und lieferte am Ende fertige Software ab. Seine Rolle habe sich vom „Steuern" zum „Beauftragen" verschoben. Ähnliche Aussagen wurden in der Vergangenheit von Boris Cherny (Entwickler von Claude Code) und Peter Steinberger (Entwickler von OpenClawd) getroffen, allerdings noch im Zusammenhang von /loops gegenüber klassischen Prompts.
Claude Fable 5 in Action: Sub-Agent Orchestrierung in Claude Code, Quelle: Byte.de
Auch das Fintech-Unicorn Strip.com hatte vorab Zugriff auf Fable 5 und konnte eine Codebase mit 50 Millionen Zeilen Ruby-Code an einem einzigen Tag migrieren. Nach Schätzungen des Teams hätten eigene Entwickler über zwei Monate für diese Aufgabe benötigt.
Kritik an Claude Fable 5
Kritik an dem Modell hält sich kurz nach dem Launch noch in Grenzen. Es lässt sich auf folgende Punkte herunterbrechen:
Fable 5 verbraucht sehr viele Tokens
Die Safety-Classifier sind sehr streng und werden zu schnell ausgelöst
Bei beiden Punkten ist davon auszugehen, dass Anthropic dies in den folgenden Wochen verbessern werden kann.
Unser größter Kritikpunkt ist die Ungewissheit, was nach dem 22.06.2026 mit dem Zugang zu Fable 5 über die Claude Subscription Modelle passieren wird. Sollte Anthropic Fable 5 wirklich zu einem API-only Modell machen, könnte das sehr teuer für uns Nutzer werden.
5. Claude Fable 5 Kosten & Verfügbarkeit
Claude Fable 5 API-Pricing
Fable 5 kostet in der reinen Token-Bepreisung über die API das Doppelte von Opus 4.8. Damit liegt es unter der Hälfte des Preises, den Anthropic für Mythos Preview aufgerufen hatte und ist somit deutlich günstiger, als erwartet:
Über die Batch API halbieren sich die Preise ($5 / $25), und Prompt Caching reduziert Input-Kosten um bis zu 90 %. Fällt eine Anfrage per Klassifizierer auf Opus 4.8 zurück, zahlst du auch nur Opus-Preise.
Was dein konkreter Workload kostet, kannst du in unserem LLM-Kosten-Rechner durchspielen.
Nutzung von Claude Fable 5 in der Claude App
In der Claude Chatbot App steht Fable 5 allen zahlenden Abonnenten (Pro, Max, Team, Enterprise) bis zum 22.06.2026 zur Verfügung.
Wer das Modell intensiv über Claude Code oder Cowork nutzen will, sollte angesichts des hohen Token-Verbrauchs direkt einen Max-Plan einplanen, denn mit dem Pro-Abo stößt man bei langen Coding-Sessions schnell an die Limits.
6. Für wen lohnt sich Claude Fable 5?
Unsere Einschätzung nach der ersten Nutzung:
Fable 5 ist ein herausragendes LLM, das nur von den hohen Kosten limitiert wird.
Jeder, der sich seriös mit KI beschäftigt, sollte ein paar Tests mit Claude Fable 5 durchführen, da das Modell eine neue Leistungsklasse eröffnet. Besonders interessant wird es für die folgenden Zielgruppen:
Entwickler mit großen Codebases: Migrationen, Refactorings und Long-Horizon-Tasks werden von Fable 5 im Handumdrehen abgearbeitet. Wer noch regelmäßig an Aufgaben mit Opus scheiterte, bekommt mit Fable 5 ein Modell, dass die Success-Rate deutlich erhöhen dürfte.
Knowledge Worker in Finance, Legal & Research: Reasoning über Dokumente, Chart-Analyse / Computer Vision Tasks und mehrstufige Analysen verbessern sich in den vorliegenden Benchmark-Ergebnissen deutlich.
Agentic-Builder: Wer Multi-Agenten-Systeme mit dem Agent SDK baut, erhält mit Fable 5 den bislang stärksten Orchestrator. Routine-Tasks werden nativ weiterhin an die günstigeren Sonnet und Haiku Modelle orchestriert.
Für den Alltagsgebrauch, einfache Texte und schnelle Recherchen bleibt Sonnet 4.6 für Gelegenheitsnutzer weiterhing die wirtschaftlichere Wahl. Auch wer hauptsächlich im Security-Umfeld arbeitet, wird mit den aktuellen Classifiern wohl eher frustriert als begeistert werden.
Fable 5 mit anderen Modellen vergleichen
In unserem interaktiven LLM-Vergleich kannst du Claude Fable 5 direkt mit anderen Frontier-Modellen von OpenAI, Google DeepMind und Co. vergleichen.
7. FAQ: Häufig gestellte Fragen zu Claude Fable 5
Was ist der Unterschied zwischen Claude Fable 5 und Claude Mythos 5?
Beide nutzen dieselben Modellgewichte. Fable 5 ist die öffentlich verfügbare Variante mit Safety-Classifiern für Cybersecurity, Biologie/Chemie und Distillation. Mythos 5 hat diese Safeguards in Teilen aufgehoben und ist ausschließlich geprüften Partnern aus Project Glasswing vorbehalten.
Ist Claude Fable 5 besser als GPT-5.5?
In den meisten veröffentlichten Benchmarks übertrifft Fable 5 die Scores von GPT-5.5 deutlich. GPT-5.5 punktet dafür beim Preis ($5/$30 vs. $10/$50) und mit dem eigenen Codex-Ökosystem. Für dein subjektives Befinden solltest du beide Modelle unabhängig voneinander testen und vergleichen.
Kann ich Claude Fable 5 kostenlos nutzen?
Nein. Fable 5 ist nur ab dem Claude Pro Plan sowie über die API kostenpflichtig verfügbar. Im Free-Plan bleibt Sonnet das stärkste verfügbare Modell.
Darstellung der Rohdaten für den Benchmark Artificial Analysis Intelligence Index. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Claude Fable 5
65 %
Claude Opus 5
61 %
Claude Opus 4.8
61 %
GPT-5.6 Sol
58,9 %
Kimi K3
57 %
GPT-5.6 Terra
55 %
Gemini 3.5 Flash
55 %
Grok 4.5
53,8 %
GPT-5.6 Luna
51,2 %
Gemini 3.6 Flash
50,1 %
MiniMax M2.7
50 %
DeepSeek-V4-Pro (Preview)
44 %
Inkling
41 %
Gemini 3.5 Flash-Lite
36,5 %
Vergleich von LLMs im Benchmark Artificial Analysis Intelligence Index. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark GDPval-AA. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Claude Fable 5
1.932 %
Claude Opus 4.8
1.890 %
Claude Opus 5
1.861 %
GPT-5.6 Sol
1.747,8 %
Gemini 3.5 Flash
1.656 %
Claude Sonnet 5
1.618 %
GPT-5.6 Terra
1.593 %
GPT-5.6 Luna
1.591,8 %
DeepSeek-V4-Pro (Preview)
1.554 %
Grok 4.5
1.543 %
MiniMax M2.7
1.495 %
Muse Spark
1.444 %
Gemini 3.6 Flash
1.421 %
Muse Spark 1.1
1.381 %
Inkling
1.238 %
Gemini 3.5 Flash-Lite
1.140 %
Vergleich von LLMs im Benchmark GDPval-AA. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark GPQA Diamond. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Fugu Ultra
95,5 %
GPT-5.6 Sol
94,6 %
Claude Mythos Preview
94,5 %
Claude Opus 4.7
94,2 %
Claude Opus 4.8
93,6 %
GPT-5.5
93,6 %
Kimi K3
93,5 %
Claude Opus 5
93,43 %
Claude Fable 5
93,18 %
Grok 4.5
93,1 %
GPT-5.6 Terra
92,9 %
Gemini 3.6 Flash
92,8 %
GPT-5.6 Luna
92,3 %
GLM-5.2
91,2 %
Kimi K2.6
90,5 %
DeepSeek-V4-Pro (Preview)
90,1 %
Muse Spark
89,5 %
Inkling
87,2 %
GLM-5.1
86,2 %
Gemini 3.5 Flash-Lite
83,8 %
Vergleich von LLMs im Benchmark GPQA Diamond. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark MCP-Atlas. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Muse Spark 1.1
88,1 %
Claude Opus 5
85,8 %
Kimi K3
84,2 %
Gemini 3.5 Flash
83,6 %
Claude Fable 5
83,3 %
Claude Opus 4.8
82,2 %
Claude Opus 4.7
77,3 %
GLM-5.2
76,8 %
GPT-5.5
75,3 %
MiniMax-M3
74,2 %
Inkling
74,1 %
DeepSeek-V4-Pro (Preview)
73,6 %
GLM-5.1
71,8 %
MiniMax M2.7
49,4 %
Vergleich von LLMs im Benchmark MCP-Atlas. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark MMMU-Pro. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Claude Opus 5
89,88 %
Claude Fable 5
89,31 %
Gemini 3.5 Flash
83,6 %
Gemini 3.6 Flash
83,2 %
GPT-5.6 Sol
83 %
Kimi K3
81,6 %
GPT-5.5
81,2 %
GPT-5.6 Terra
80,7 %
Grok 4.5
80,4 %
Muse Spark
80,4 %
Kimi K2.6
79,4 %
Gemini 3.5 Flash-Lite
79 %
GPT-5.6 Luna
78,4 %
MiniMax-M3
78,1 %
Gemma 4 31B
76,9 %
Inkling
73,5 %
Vergleich von LLMs im Benchmark MMMU-Pro. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark OSWorld-Verified. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Claude Fable 5
85 %
Claude Opus 4.8
83,4 %
Gemini 3.6 Flash
83 %
Claude Sonnet 5
81,2 %
Muse Spark 1.1
80,8 %
Claude Mythos Preview
79,6 %
GPT-5.5
78,7 %
Gemini 3.5 Flash
78,4 %
Claude Opus 4.7
78 %
GPT-5.4
75 %
Gemini 3.5 Flash-Lite
74 %
Kimi K2.6
73,1 %
Claude Opus 4.6
72,7 %
Claude Sonnet 4.6
72,5 %
MiniMax-M3
70,06 %
Claude Opus 4.5
66,3 %
GPT-5.3-Codex
64,7 %
Claude Haiku 4.5
50,7 %
GPT-5.4 mini
42 %
Vergleich von LLMs im Benchmark OSWorld-Verified. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark SWE-bench Pro. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Claude Fable 5
80 %
Claude Opus 5
79,2 %
Fugu Ultra
73,7 %
Claude Opus 4.8
69,2 %
Grok 4.5
64,7 %
GPT-5.6 Sol
64,6 %
GPT-5.6 Terra
63,4 %
Claude Sonnet 5
63,2 %
GPT-5.6 Luna
62,7 %
GLM-5.2
62,1 %
Muse Spark 1.1
61,5 %
Laguna S 2.1
59,4 %
MiniMax-M3
59 %
Gemini 3.6 Flash
58,7 %
GPT-5.5
58,6 %
Kimi K2.6
58,6 %
DeepSeek-V4-Pro (Preview)
55,4 %
Gemini 3.5 Flash
55,1 %
Inkling
54,3 %
Gemini 3.5 Flash-Lite
54,2 %
Vergleich von LLMs im Benchmark SWE-bench Pro. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark SWE-bench Verified. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
GPT-5.6 Sol
96,2 %
Claude Opus 5
96 %
Claude Fable 5
95 %
Claude Mythos Preview
93,9 %
Claude Opus 4.8
88,6 %
Claude Opus 4.7
87,6 %
Claude Sonnet 5
85,2 %
Claude Opus 4.6
80,8 %
DeepSeek-V4-Pro (Preview)
80,6 %
Gemini 3.1 Pro
80,6 %
MiniMax-M3
80,5 %
Kimi K2.6
80,2 %
MiniMax M2.5
80,2 %
MiniMax M2.7
79,9 %
Claude Sonnet 4.6
79,6 %
GLM-5
77,8 %
Inkling
77,6 %
Muse Spark
77,4 %
Qwen3.5-397B-A17B
76,4 %
GPT-5.6 Terra
75,2 %
Vergleich von LLMs im Benchmark SWE-bench Verified. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark Terminal-Bench 2.1. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
GPT-5.6 Sol
88,8 %
Kimi K3
88,3 %
GPT-5.6 Terra
87,4 %
GPT-5.6 Luna
84,7 %
Claude Opus 5
84,64 %
Claude Fable 5
84,3 %
Grok 4.5
83,3 %
GLM-5.2
82,7 %
Fugu Ultra
82,1 %
Claude Sonnet 5
80,4 %
Muse Spark 1.1
80 %
Gemini 3.6 Flash
78 %
Gemini 3.5 Flash
76,2 %
Claude Opus 4.8
74,6 %
Laguna S 2.1
70,2 %
MiniMax-M3
66 %
Inkling
63,8 %
Gemini 3.5 Flash-Lite
54 %
MiniMax M2.7
51,1 %
Vergleich von LLMs im Benchmark Terminal-Bench 2.1. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Darstellung der Rohdaten für den Benchmark Vending-Bench 2. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.
Modell
Score
Claude Fable 5
5.680,26 %
GLM-5.1
5.634,41 %
Claude Opus 4.8
2.992,34 %
Vergleich von LLMs im Benchmark Vending-Bench 2. Der niedrigste Score im Benchmark ist 0 % und der höchste Score ist 100 %.